728x90
파이썬을 이용해서 구글에서 필요한 이미지 크롤링하는 방법!!
1. 필요한 패키지를 다운 받는다.
pip install beautifulsoup4 pip install selenium pip install requests
2. import 패키지
from urllib.request import urlretrieve from urllib.parse import quote_plus from bs4 import BeautifulSoup as BS from selenium import webdriver
3. Url 가져오기
구글에서 이미지를 검색해보면 빨간색 네모의 단어만 변경되는 걸 볼 수 있다.

코드는 빨간 네모를 변수 지정하고 나머지는 동일 하니 그대로 붙여놓기
keyword = input("Image Name : ")
i_URL = f'https://www.google.com/search?q={quote_plus(keyword)}&sxsrf=ALeKk00OQamJ34t56QSInnMzwcC5gC344w:1594968011157&source=lnms&tbm=isch&sa=X&ved=2ahUKEwjXs-7t1tPqAhVF7GEKHfM4DqsQ_AUoAXoECBoQAw&biw=1536&bih=754'
4. 크롬 드라이버를 로딩하고 Url 접속 하기
driver=webdriver.Chrome('C://chromedriver.exe') #크롬 드라이버
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-logging'])
driver.get(i_URL)5. 다운로드하기
검색하고, 다운로드하고, 종료되면 크롬 드라이버를 종료한다.
html = driver.page_source
soup = BS(html,features="html.parser")
img = soup.select('img')
i_list = []
count = 1
print("Searching...")
for i in img:
try:
i_list.append(i.attrs["src"])
except KeyError:
i_list.append(i.attrs["data-src"])
print("Downloading...")
for i in i_list:
urlretrieve(i,"download/"+keyword+str(count)+".jpg")
count+=1
driver.close()
print("FINISH")실행 화면

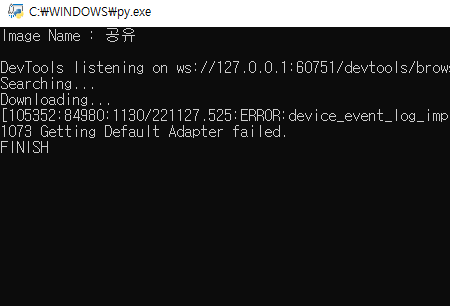
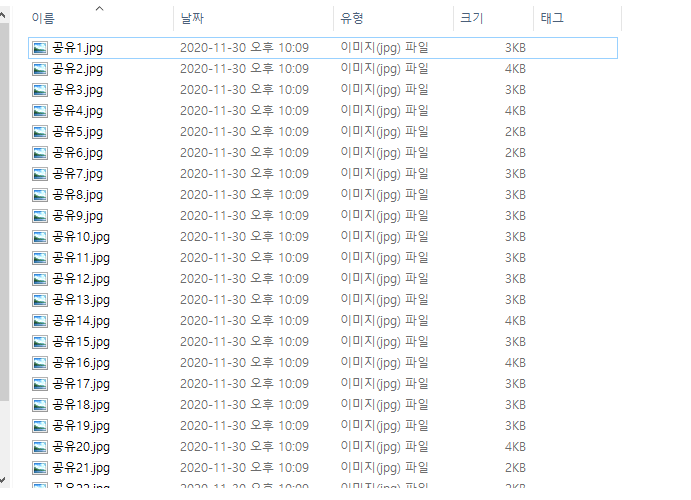
구글에서 검색된 공유 이미지를 다운로드할 수 있다.
실행 영상
728x90
'개발공부 > Python' 카테고리의 다른 글
| 파이썬으로 네이버 주식 현재가 가져오기 (28) | 2020.12.04 |
|---|---|
| 초등학생도 할 수 있는 머신러닝 학습 시키기 (15) | 2020.12.02 |
| 로또 홈페이지에서 당첨번호 1회 부터 엑셀 뽑기 (14) | 2020.11.22 |
| 클라우드 개발 환경 구름 IDE (6) | 2020.11.21 |
| 파이썬 pyautogui 마우스/키보드 자동화#3 (5) | 2020.11.21 |